
光通訊封裝大轉場(二):CPO 三段式進化,為什麼 OBO 死了、scale-out 先動、scale-up 才是終局
- 6月4日
- 讀畢需時 5 分鐘
CPO(co-packaged optics)這個詞至少喊了五年,每年 OFC 都有人說「明年就要量產」,但 pluggable optics 一年比一年賣得好。直到 2025 年 GTC,Nvidia 把 Spectrum-X Photonics 攤在桌上,Broadcom 把 Tomahawk CPO 送進 Meta 測試實驗室,TSMC 把 COUPE 從 demo 升級成 production-ready——這一年市場才接受 CPO 真的要來了。
但 CPO 不會「取代」pluggable。綜合產業推估,pluggable optical transceiver 2031 年仍會成長到 $7.8B(CAGR 約 10%),而 CPO(含 OBO、NPO、scale-out、scale-up)會從 2025 年 $0.1B 衝到 $5.1B(CAGR 約 92%)。這是兩個並行的市場,不是替代關係。
這篇要拆的是:為什麼 OBO 與 NPO 死了?為什麼 scale-out CPO 先動?為什麼 scale-up CPO 才是真正的長期賽道?
1. 失敗的兩個前哨:OBO 與 NPO
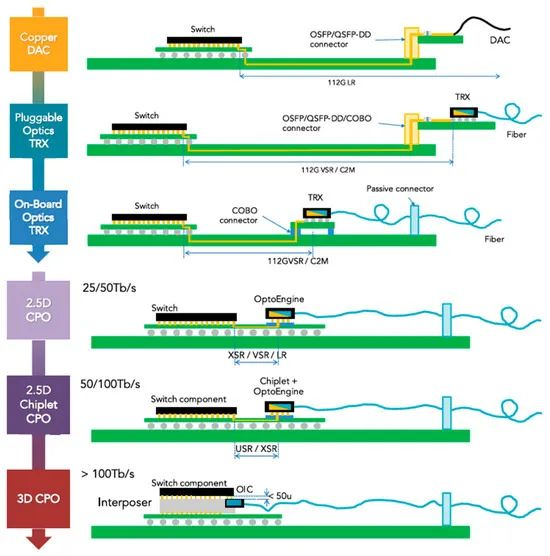
CPO 之前,業界試過兩個「把光拉近 ASIC」的方案——OBO(on-board optics)與 NPO(near-packaged optics)。兩個都死在量產關口。
OBO 的核心想法:把光模組從面板上拉到主機板上,靠 socketed connector 連回 switch ASIC。優點是降低面板拔插的功耗與訊號損失,缺點是改了 ASIC 也改了 PCB,整個 form factor 重新設計。COBO(Consortium for On-Board Optics)2016 年成立,2018 年 Delta 與 Microsoft 做出概念驗證,之後就停了——hyperscaler 不想為了一點 power saving 改整個 PCB 架構,pluggable 的 modularity 太香了。
NPO 的核心想法:把光引擎更靠近 switch ASIC,放在同一個 multi-chip module 旁邊,靠 socketed optical connector 接外部 laser module。比 OBO 更激進,但仍保留可拔插的 optical engine。Ragile Networks 做過樣品,停在實驗室。
OBO 和 NPO 最終都成了「proof of concept」三個字的同義詞。
它們失敗的原因不是技術,是時機。2018–2022 年那段時間,pluggable 從 100G 升到 400G 再到 800G,每一代 SerDes 的功耗都還能擠下去。Hyperscaler 沒有非改不可的痛點,自然不會接受 OBO/NPO 帶來的 form factor 與供應鏈重組成本。
真正讓 CPO 動起來的,是 51.2T 這個門檻。51.2T 之後,每 lane 的速度從 100G 拉到 200G,再之後是 400G 與 800G。電的限制變成硬牆——SerDes 功耗、PCB 訊號 reach、面板 beachfront density 全部撞牆。這時候光不再是 nice-to-have,是 must-have。
2. Scale-out 先動:51.2T 的轉折點
CPO 第一個吃下的場景是 scale-out network——資料中心內 GPU cluster 之間、rack 之間的水平互連。為什麼是這裡先動?三個結構性原因:
原因一:交換器頻寬已經撞牆。從 25.6T(4 × 3.2T)一路衝到 102.4T、204.8T、409.6T,每一代靠加大 ASIC + 加快 SerDes 已經不夠。Nvidia 的 Quantum-X800 InfiniBand 在 2025 下半年用 CPO 推到 115.2T,Spectrum-X 在 2026–2027 年會分別推出 SN6810(2RU)與 SN6800(6RU)以太網交換機,目標 409.6T。

原因二:scale-out 拓樸已經穩定。spine-leaf-TOR 架構已成標準,CPO 進場不需要重新設計 cluster topology——只是把 switch 從 pluggable 換 CPO,整個 fabric 邏輯不變。這對 hyperscaler 是低風險升級。
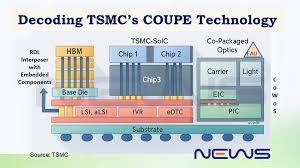
原因三:早期 deployment 可以用 2.5D 整合。switch ASIC 與 optical engine(EIC + PIC)放在同一塊 substrate 上、靠 advanced IC substrate 連接就行,不需要走到 3D hybrid bonding 的極限。這讓 TSMC COUPE 與 ASE FOCoS 在 2025–2027 就能量產交付。
預估 scale-out CPO 的 volume 會從 2025 年的 39k unit 衝到 2031 年的 5.97M unit,CAGR 約 131%。對應營收從 $103M 到 $3.95B。
但這只是熱身。真正撐起 CPO 第二個十年的是 scale-up。
3. Scale-up 才是終局:把光放進 GPU 旁邊
Scale-up network 指的是同一個 server 或同一個 multi-die package 內、GPU 跟 GPU 之間、GPU 跟 HBM 之間的高頻寬低延遲互連。這條鏈現在靠 NVLink(Nvidia)、Infinity Fabric(AMD)、ICI(Google TPU)、NeuronLink(Amazon Trainium 2)——全部都是銅,靠 die-to-die copper trace 或 fly-over cable。
問題:當 cluster 從 8 顆 GPU(H100)拉到 72 顆(B200),再往 144 甚至 256 顆衝,銅的物理極限就到了。每一條 link 的 power 都要 1+ pJ/bit,加上散熱,cluster 規模愈大愈不划算。
光的承諾在這裡更狠:advanced CPO 架構可以做到 sub-1 pJ/bit、配合 30–50% 的 system-level power saving。對 hyperscaler 來說,這是 hyperscale-scale 的差別。
但 scale-up CPO 的封裝難度比 scale-out 高一個檔次:
必須走 3D 堆疊:EIC 在 PIC 上面(或反過來),通過 hybrid bonding 或 fan-out 直連,TSV 走訊號
PIC 不只當 transceiver,要當 interposer:未來架構是 PIC 直接當作 HBM 與 GPU 之間的光學 interposer
散熱要重新設計:3D 堆疊讓熱島集中,光學元件對溫度漂移敏感(雷射波長會跑、ring resonator 會偏)

預估 scale-up CPO 的 volume 會從 2025 年的 33k unit 衝到 2031 年的 15.2M unit,CAGR 約 178%。對應營收從 $30M 到 $3.7B。注意這個 178% 的 CAGR——它意味著 2028 年才會真正起飛,而非 2026。 對 fabless 設計與 OSAT 來說,這給出三年窗口期準備產能。
4. 三段式進化的時間軸
把整個演進拉成一條時間線:
時期 | 主場 | 封裝重點 | 代表廠商 |
2018–2025 | Pluggable 主導,OBO/NPO 死於概念驗證 | Module 組裝、hybrid integration | Innolight、Eoptolink、Fabrinet、Jabil、Luxshare |
2025–2027 | CPO scale-out 起跑 | 2.5D advanced packaging、EIC-PIC 堆疊 | TSMC(COUPE)、ASE(FOCoS)、Nvidia、Broadcom |
2027–2030 | CPO scale-up 起飛 | 3D hybrid bonding、heterogeneous integration of laser | TSMC、Intel(OCI)、Marvell-Celestial AI、Lightmatter |
2030+ | SiPh interposer 終局 | PIC 當 active interposer,TFLN/BTO 等新材料平台 | 上述同一批,加入 AyarLabs 等 chiplet 玩家 |
Optical transceiver 端的進化軸線是並行的:
2024 之前:hybrid die attach(flip-chip 雷射)為主
2026–2028:轉向 heterogeneous die attach(Intel-style InP 雷射 wafer-level integration)
2028+:新材料平台(TFLN、BTO)進場做 modulator,heterogeneous + hybrid 整合並存
5. Nvidia 與 Broadcom 走的不是同一條路
scale-out CPO 第一批量產,Nvidia 與 Broadcom 的架構選擇值得拆開看,因為它預告了未來標準怎麼定。
Nvidia Quantum-X 走 3D 堆疊 + TSMC COUPE 路線。每個 optical engine 有 3 個 PIC-EIC 堆疊,EIC 與 PIC 用 TSMC 的 SoIC-X 做 die-to-wafer hybrid bonding。switch ASIC 與 optical engine 都坐在同一個 advanced IC substrate 上,是 multi-chip FCBGA。modularity 設計讓 Nvidia 可以用同樣的 ASIC 配不同的 PIC,未來換代時不需要重做整個架構。
Broadcom Tomahawk CPO 走 fan-out wafer-level packaging 路線。8 個 optical engine 環繞 ASIC,每個 engine 有 64 TX + 64 RX channel,每 channel 100 Gb/s。SiPh chiplet 用 dual-side fanout 把 PIC 疊在 CMOS EIC 上,避開複雜的 TSV。對外用 detachable 127μm-pitch optical connector,可以現場換光纖。

兩家走兩條路,恰好對應 TSMC(hybrid bonding)與 ASE(fan-out)的平台差異。
這不是巧合。Nvidia 與 TSMC 走 CoWoS 已經幾年,CPO 自然延續 TSMC 的 hybrid bonding 路線;Broadcom 與 ASE/SPIL 的關係深厚(ASE 在 2023 已進入 Broadcom SiPh 後段封裝鏈),CPO 就走 ASE 的 fan-out 平台。
未來 1.6T 與更高速 CPO 的標準之爭,本質上是 TSMC vs ASE 兩個 advanced packaging 平台的競爭。這是下一篇要拆的主題。
6. 結論:CPO 是 additional market,不是 replacement
回到開頭那個重點:CPO 不是 pluggable 的繼任者,是新增的市場。理由很簡單——pluggable 仍然是 short-reach、低密度應用最划算的方案,DR4/FR4/LR4 這些 800G 規格的銷量會持續成長到 2030 年。
CPO 真正解決的是「pluggable 解不了的場景」:
51.2T 以上的高密度 switch
GPU cluster 內部 ultra-high bandwidth 互連
多 die package 內部 PIC-as-interposer 架構
這三個場景共同的特徵都是「高度 customized、與 ASIC roadmap 綁死」。這也是為什麼 CPO 的供應鏈集中度會比 pluggable 高很多——能跟 Nvidia 或 Broadcom 共同設計 SiPh + advanced packaging 的玩家屈指可數,台灣的 TSMC、ASE、SPIL 加上美國的 Intel、Marvell,幾乎就是全部。
CPO 是個慢起跑、快起飛的故事。2025–2027 看 scale-out 跑得多快,2027–2030 看 scale-up 怎麼長,2030+ 看 SiPh interposer 能不能成為新典範。這條進化軸線會用十年走完,每一段都會重塑光通訊封裝的權力結構。


''CPO 不會「取代」pluggable。綜合產業推估, pluggable optical transceiver 2031 年仍會成長到 $7.8B(CAGR 約 10%),而 CPO(含 OBO、NPO、scale-out、scale-up)會從 2025 年 $0.1B 衝到 $5.1B(CAGR 約 92%)** 。這是兩個並行的市場,不是替代關係。'' (筆記筆記) 謝謝分享~